9. Program structure and compilation¶
9.1. The compilation process¶
For a C program of any reasonable size, it is convenient to separate the functions that comprise the program into different text files. There are standard ways to organize source code in order to allow the functions in separate files to cooperate, and yet allow the compiler to build a single executable.
The process of compiling C programs is different than with Java, and has important implications for how source code must be organized within files. In particular, C compilers make a single (top-to-bottom) pass over source code files. This process is very much unlike the Java compiler, which may make multiple passes over the same file, and which may automatically compile multiple files in order to resolve code dependencies (e.g., if a class is used in one file but defined in another, the compiler will compile both files). In C, it is entirely up to the programmer to decide which files need to be compiled and linked to produce an executable program.
There are three basic steps involved in compiling a C program: preprocessing, compilation of C source code to machine code (or assembly) (also called object code), and linking of multiple object files into a single binary executable program. Each of these steps are described below.
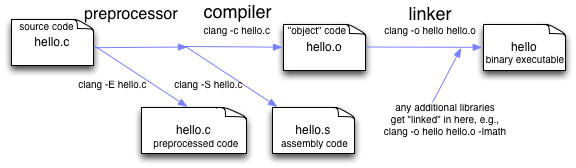
The three basic steps when compiling C programs are preprocessing, compilation, and linking.¶
9.1.1. The preprocessing step¶
The preprocessing step happens just prior to the compilation phase. The C preprocessor looks for any preprocessor directives in the source code, which are any lines starting with #. The preprocessor then performs some actions specified by the directive. The text resulting from the preprocessor's action is then fed directly (and automatically) to the compilation phase.
Since a C compiler makes a single pass over a .c file, it must be made aware of all the types and signatures in order to correctly and successfully complete the compilation process. That is, if an unknown data type is encountered in the single top-to-bottom pass, the compiler will report an error. For example, here is some source code that will not compile correctly:
#include <stdlib.h>
int main() {
struct function f1 = { 1,2};
return EXIT_SUCCESS;
}
struct function {
int numerator;
int denominator;
};
Why does it fail? Simply because the definition of struct function comes after its first use. To make the code correctly compile, the struct definition must precede main.
9.1.1.1. Header (.h) and source (.c) files¶
Because of the single-pass top-to-bottom operation of C compilers, each source file (each .c file) must identify all data types and function signatures that are used in that file in order to make the code successfully compile. The standard practice in C is to define any types and declare any functions in header files (.h files) in order to facilitate the compilation process. In one sense, you can think of the .h files as containing the "external interfaces" (i.e., the API) and data types used for a set of functions, and the corresponding .c file as containing the actual function definitions.
For example, say that we want to define the struct fraction type and a couple utility functions that can be used in other .c files. We might define a fraction.h file that contains the following:
struct fraction {
int numerator;
int denominator;
};
void print_fraction(const struct fraction *);
void invert_fraction(struct fraction *);
Notice that this header file contains the struct definition, and two function prototypes. A "prototype" for a function gives its name and arguments but not its body. The function parameters do not even have to have variable names (as they're shown above), but there's no problem if they do include the parameter names.
The corresponding fraction.c file might contain the following:
#include "fraction.h"
void print_fraction(const struct fraction *f) {
printf("Fraction: %d/%d\n", f->numerator, f->denominator);
}
void invert_fraction(struct fraction *f) {
int tmp = f->numerator;
f->numerator = f->denominator;
f->denominator = tmp;
}
Notice that the first line of code in fraction.c is #include "fraction.h". Any line of code that begins # is called a preprocessor directive. We have used #include quite a bit so far. Its meaning is simply to directly replace the #include directive with the text in the specified file name.
A file that uses the fraction utility functions in a file called test.c might look like the following:
#include "fraction.h" // include struct fraction definition and
// fraction utility function prototypes,
// as well as other headers like stdlib.h
int main() {
struct fraction f = {2,3};
invert_fraction(&f);
print_fraction(&f);
return EXIT_SUCCESS;
}
9.1.1.2. Preprocessor directives¶
There are several preprocessor directives that can be listed in C source code. #include and #define are the two most common, but there are others.
9.1.1.3. #include¶
As we've already seen, the #include directive reads in text from different files during the preprocessing step. #include is a very unintelligent directive --- the action is simply to paste in the text from the given file. The file name given to #include may be included in angle brackets or quotes. The difference is that system files should be enclosed in angle brackets and any user files should be enclosed in quotes.
9.1.1.4. #define¶
The #define directive can be used to set up symbolic replacements in the source. As with all preprocessor operations, #define is extremely unintelligent --- it just does textual replacement without any code evaluation. #define statements are used as a crude way of establishing symbolic constants or macros. Generally speaking, you should prefer to use const values over #define directives.
Here are examples of quasi-constant definitions:
#define MAX 100
#define SEVEN_WORDS that_symbol_expands_to_all_these_words
Later code can use the symbols MAX or SEVEN_WORDS which will be replaced by the text to the right of each symbol in its #define.
Simplistic macro functions can also be defined with #define directives. For example, a commonly used macro is MAX, which takes two parameters and can be used to determine the larger of two values:
#define MAX(a,b) (a > b ? a : b)
Again, the #define directive is incredibly unintelligent: it is simply smart enough to do textual replacement. For example, the following code:
int a = MAX(c, d);
would be replaced by the preprocessor with the following:
int a = (c > d ? c : d);
While MAX is often referred to as a macro function (or simply macro), it does not operate as a function at all. The programmer can (somewhat) treat the macro as a function, but the effect is just an illusion created by the C preprocessor.
9.1.1.5. #if¶
At the preprocessing phase, the symbolic names (and values) defined by #define statements and predefined by the compiler can be tested and evaluated using #if directives. The #if test can be used at the preprocessing phase to determine whether code is included or excluded in what is passed on to the compilation phase. The following example depends on the value of the FOO #define symbol. If it is true (i.e., non-zero), then the "aaa" lines (whatever they are) are compiled, and the "bbb" lines are ignored. If FOO is false (i.e., 0), then the reverse is true.
#define FOO 1
...
#if FOO
aaa
aaa
#else
bbb
bbb
#endif
Interestingly (and usefully), you can use #if 0 ...#endif to effectively comment out areas of code you don't want to compile, but which you want to keep in the source file.
9.1.1.6. Multiple #includes¶
It is invalid in C to declare the same variable or struct twice. This can easily happen if a header file is #included twice. For example, if a source code file includes header file A and B, and header file B also includes header file A, the contents of header file A will be included twice, which may cause problems.
A standard practice to avoid this problem is to use the #ifndef directive, which means "if the following symbol is not defined, do the following". The #define symbol is often based on the header file name (as in the following), and this practice
This largely solves multiple #include problems.
#ifndef __FOO_H__
#define __FOO_H__ // we only get here if the symbol __FOO_H__ has not been previously defined
<rest of foo.h ...>
#endif // __FOO_H__
9.1.1.7. Invoking the preprocessor¶
Normally, you do not need to do anything special to invoke the preprocessing phase when compiling a program. It is, however, possible to only invoke the preprocessing phase (i.e., no compilation or anything else), and also to define new preprocessor symbols on the command line.
To invoke just the preprocessor in clang, you can use the command clang -E sourcefile.c. clang has another command line option to just run the preprocessor and check code syntax: clang -fsyntax-only sourcefile.c.
To define new preprocessor symbols (i.e., just like #define), the -D option can be used with clang, as in clang -DSYMBOL, or clang -DSYMBOL=VALUE.
9.1.2. The compilation step¶
The compilation step takes as input the result from the preprocessing stage. Thus, any # directives have been processed and are removed in the source code seen by the compiler.
The compilation stage can produce either assembly code or an object file as output. Typically, the object code is all that is desired; it contains the binary machine code that is generated from compiling the C source. There are a few different relevant compiler options at this stage:
- clang -S sourcefile.c
Produces assembly code in sourcefile.s
- clang -c sourcefile.c
Produce object file (binary machine code) in sourcefile. This is the more common option to employ for the compilation stage. When all source files have been compiled to object code (
.ofiles), all the.ofiles can be linked to produce a binary executable program.
Some additional compiler options that are useful at this stage:
option |
meaning |
|---|---|
-g |
include information to facilitate debugging using a program like gdb. |
-Wall |
Warn about any potentially problematic constructs in the code. |
9.1.3. The linking phase¶
The linking stage takes 1 or more object files and produces a binary executable program (i.e., a program that can be directly executed on the processor). It requires two things: that the implementations for any functions referenced in any part of the code have been defined, and that there is exactly one main function defined.
9.1.3.1. Options for linking¶
In the simplest case, there is only one source file to preprocess, compile, and link. In that case, the same command line we've used with clang so far does the trick:
clang -g -Wall inputfile.c -o myprogram
or, if you've already compiled inputfile.c to inputfile.o, just:
clang -g -Wall inputfile.o -o myprogram
In a more "interesting" case, there is more than one file to compile and link together. For each source file, you must compile it to object code. Following that, you can link all the object files together to produce the executable:
clang -g -Wall file1.c -c
clang -g -Wall file2.c -c
clang -g -Wall file3.c -c
clang -g file1.o file2.o file3.o -o myprogram
If you use functions from the standard C library, you don't need to do anything special to link in the code that implements the functions in that library. If, however, your program uses a function from an external library like the math library (see man 3 math; it contains functions such as log2, sqrt, fmod, ceil, and floor), the library to be linked with must be specified on the command line. The basic command is:
clang -g -Wall inputfile.o -o outputfile -lmath
The -l option indicates that some external library must be linked to the program, in this case the math library.
9.1.3.2. The main function¶
The execution of a C program begins with the function named main. All of the files and libraries for the C program are compiled together to build a single program file. That file must contain exactly one main function which the operating system uses as the starting point for the program. main returns an int which, by convention, is 0 if the program completed successfully and non-zero if the program exited due to some error condition. This is just a convention which makes sense in shell oriented environments such as UNIX.
9.1.3.3. Command-line arguments to a program¶
For many C programs, it is useful to be able to pass various command-line arguments to the program through the shell. For example, if we had a program named myprogram and we wanted to give it the names of several text files for it to process, we might use the following command line:
$ ./myprogram file1.txt file2.txt file3.txt
Each of the file names (file1-3.txt) is a command-line parameter to the program, and can be collected through two parameters to main which are classically called argc and argv and are declared as follows:
int main(int argc, char *argv[]) {
// ...
}
The meaning of these parameters is:
argcThe number of command-line arguments given to the program, including the program name
argvAn array of C strings which refer to each of the command-line parameters. Note that
argv[0]is always the name of the program itself. For example, in the above command line,argv[0]would be"./myprogram".
A simple program that traverses the array of command-line arguments and prints each one out could be written as follows:
#include <stdio.h>
#include <stdlib.h>
int main(int argc, char *argv[]) {
for (int i = 0; i < argc; i++) {
printf("argument %d is %s\n", i, argv[i]);
}
return EXIT_SUCCESS;
}
There is a C library function called getopt that enables parsing of options in more flexible ways. See man 3 getopt for more information.
9.2. Invariant testing and assert¶
Array out of bounds references are an extremely common form of C run-time error. You can use the assert() function to sprinkle your code with your own bounds checks. A few seconds putting in assert statements can save you hours of debugging.
Getting out all the bugs is the hardest and scariest part of writing a large piece of software. Adding assert statements are one of the easiest and most effective helpers for that difficult phase.
#include <assert.h>
#define MAX_INTS 100
void somefunction() {
// ...
int ints[MAX_INTS];
i = foo(<something complicated>);
// i should be in bounds,
// but is it really?
assert(i>=0); // safety assertions
assert(i<MAX_INTS);
ints[i] = 0;
// ...
Depending on the options specified at compile time, the assert() expressions will be left in the code for testing, or may be ignored. For that reason, it is important to only put expressions in assert() tests which do not need to be evaluated for the proper functioning of the program.
int errCode = foo(); // yes --- ok
assert(errCode == 0);
if (assertfoo() == 0) ... // NO, foo() will not be called if
// the compiler removes the assert()